Today I was informed that I have received a Microsoft MVP award for Visual Studio – Solutions Architect. You can check out my profile on the MVP site here. I would like to thank everyone, my wife and children especially, for all the support and encouragement over the years. A special thanks to my fellow plumbers (John Bristowe, Bil Simser, and Dan Sellers), the Calgary .NET User Group (big kudos to Jean-Paul Boodhoo and Daniel Carbajal), and the entire EDMUG crew (Donald Belcham, Stephen Rockarts, Justice Gray, Steve Yang, and Brad Daoust). Enjoy the link love, guys! 
What is SecurityKicks.com?
SecurityKicks.com is a community-based news site edited by our members. It specialises in security information for developers, including writing secure code, authentication and authorization techniques, cryptography, and related topics.
Individual users of the site submit and review stories, the most popular of which make it to the homepage. Users are encouraged to ‘kick’ stories that they would like to appear on the homepage. If a story receives enough kicks, it will be promoted.
What is a kick?
Kicks are votes of approval from our members. If a story has 16 kicks, that means 16 users liked it. The more kicks a story receives, the more likely that it will appear on the homepage. If you don’t like a story, don’t give it a kick.
How do I submit stories?
You simply need to register for a new account. With an account you can submit stories by clicking the ‘Submit a story’ link on the right menu of the homepage.
How do I find stories?
To find stories that have not been promoted, click the ‘Find stories‘ link on the right menu of the homepage. You can also click the ‘find’ link beside each category in the list of categories.
Who are the brains behind this operation?
The original idea for the site was mine, but Gavin Joyce, creator of DotNetKicks.com, deserves the bulk of the credit. He not only set up the site, but is also hosting it. Hats off to Gavin!
I hope you find SecurityKicks.com to be a useful resource for finding developer-related security information. Welcome and enjoy!
The Edmonton Code Camp was a blast. John Bristowe and I drove up Saturday morning and returned late Saturday night. There were lots of action packed presentations throughout the day, but Jean-Paul Boodhoo stole the show as per usual. His presentation on cool things you can do with generics was excellent and there was not a PowerPoint slide to be seen. It was a nice contrast to my PowerPoint-heavy Tools of the Trade: Must-Have .NET Utilities (PowerPoint 2007 slidedeck), which was on right before. (Maybe I’ll try doing that presentation without the PowerPoint crutch next time.)  Thanks to everyone who came to my talk and especially those who asked questions. To save people from having to download the slidedeck just to get the links, here is the tools that I talked about in raw, unadulterated HTML:
Thanks to everyone who came to my talk and especially those who asked questions. To save people from having to download the slidedeck just to get the links, here is the tools that I talked about in raw, unadulterated HTML:
The Holy Trinity
- NUnit (http://www.nunit.org)
- Unit testing framework
- See also:
- TestDriven.NET (http://www.testdriven.net)
- NAnt (http://nant.sourceforge.net)
- Make without the wrinkles
- See also:
- NAntContrib (http://nantcontrib.sourceforge.net)
- MSBuild (VS 2005)
- NDoc (http://ndoc.sourceforge.net)
- API documentation generator for .NET Framework v1.X
- See also:
- Sandcastle (http://www.sandcastledocs.com)
- Sandcastle Builder (http://www.codeproject.com/useritems/SandcastleBuilder.asp)
- GhostDoc (http://www.roland-weigelt.de/ghostdoc)
Source Control
- Subversion
- Subversion server (http://subversion.tigris.org)
- Command-line BerkeleyDB or file system backend
- TortoiseSVN (http://tortoisesvn.tigris.org)
- Explorer extension
- RapidSVN (http://rapidsvn.tigris.org)
- Traditional VSS-style GUI
- AnkhSVN (http://ankhsvn.tigris.org)
- Visual Studio add-in
- vss2svn (http://vss2svn.tigris.org)
- Perl script to convert VSS DB to SVN
- SourceGear Vault (http://www.sourcegear.com/vault/) $$$
- VSS- or CVS-style check-ins
- SQL Server DB backend
- Team Foundation Server (TFS) $$$
- SQL Server 2005 backend
- Includes project portal, work item tracking, process enforcement, build server, reports, etc.
- Requires Visual Studio Team System (VSTS)
Code Analysis Tools – Static
- FxCop (http://www.gotdotnet.com/team/fxcop/)
- Analyzes code against a rules database including coding standards, best practices, and defects
- LibCheck (http://www.microsoft.com/downloads/details.aspx?FamilyID=4B5B7F29-1939-4E5B-A780-70E887964165&displaylang=en)
- Displays API differences between two assemblies
Code Analysis Tools – Dynamic
- NCover (http://www.ncover.org/)
- Analyzes code coverage
- NProf (http://nprof.sourceforge.net)
- JetBrains dotTrace Profiler (http://www.jetbrains.com/profiler/) $$$
- Profiles application performance
- CLR Profiler (http://www.microsoft.com/downloads/details.aspx?familyid=A362781C-3870-43BE-8926-862B40AA0CD0&displaylang=en)
- Profiles allocations and garbage collections
Build Tools
- CruiseControl .NET (http://ccnet.thoughtworks.com/)
- Continuous integration server Builds via NAnt, MSBuild, DevEnv, or custom
- Runs unit testing (NUnit), coverage (NCover) and/or code analysis (FxCop) on builds (optional)
- Reports build and/or test failures via email
- Dashboard (ASP.NET app) shows current and past build status
Debugging Tools
- Lutz Roeder’s Reflector (http://www.aisto.com/roeder/dotnet/)
- Reverse engineers MSIL into C#, VB.NET, or Delphi
- See also:
- FileDisassembler Add-in (http://www.denisbauer.com/NETTools/FileDisassembler.aspx)
- Reflector Diff Add-in (http://www.codingsanity.com/diff.htm)
- ClrSpy (http://www.gotdotnet.com/Community/UserSamples/Details.aspx?SampleGuid=c7b955c7-231a-406c-9fa5-ad09ef3bb37f)
- Exposes Customer Debug Probes (CDP) for diagnosing problems with COM Interop and P/Invoke
- Fiddler (http://www.fiddlertool.com)
- HTTP debugging proxy, which logs all HTTP traffic between your browser and the network
- Allows you to “fiddle” and replay requests
- XmlSerializerPreCompiler (http://www.sellsbrothers.com/tools/#XmlSerializerPreCompiler)
- Fantastic tool for debugging mysterious XmlSerializer exceptions
- Everything by SysInterals.com! (http://www.sysinternals.com)
- Tools for monitoring disk, files, handles, registry, processes, and more
Coding Tools
- Notepad2 (http://www.flos-freeware.ch/notepad2.html)
- Notepad++ (http://notepad-plus.sourceforge.net/)
- Both excellent Notepad replacements
- CopySourceAsHtml (http://www.jtleigh.com/people/colin/software/CopySourceAsHtml/)
- Visual Studio Add-in for copying source code as HTML
- RegexDesigner.NET (http://www.sellsbrothers.com/tools/#regexd)
- Runs regular expressions using System.Text.RegularExpressions
- pinvoke.net (http://www.pinvoke.net)
- Public wiki for P/Invoke signatures
- CodeRush (http://www.devexpress.com/Products/NET/CodeRush/) $$$
- Intuitive coding tool
- Refactor Pro! (http://www.devexpress.com/Products/NET/Refactor/) $$$
- Refactoring tool with awesome previews
- ReSharper (http://www.jetbrains.com/resharper/) $$$
- Refactoring/coding tool with excellent support for TDD and personal favourite
I’ve been a big believer in unit testing for years now, but was never serious about test-driven development (TDD) until a few months ago. It sounded like an interesting idea, but I didn’t understand why TDD practitioner were so zealous about writing the tests first. Why did it matter? I thought it was to ensure that some project manager doesn’t try to shave some time off the project by cutting the unit tests. Then I started doing some reading about TDD, poking around, asking questions, and trying it out myself. I discovered the real reason for writing tests first is that TDD isn’t about testing code, it’s about designing code. That was my first epiphany. You need to write the tests first because you’re designing how the code works. This isn’t some eggheaded “let’s make pretty UML” diagrams.* We’re actually specifying our object’s API and writing working code. At first our test will fail because the code to implement the behaviour we’re designing hasn’t been written yet. NUnit comes up RED! Now we implement the functionality we just specified.** NUnit comes up GREEN! How does this fit in with the rest of our design? Can we extract commonalities? Can we make our overall design better? REFACTOR! (NUnit should still be green because refactoring shouldn’t change behaviour.) So that’s where we get the TDD mantra: Red-Green-Refactor. When you get into the rhythm, it feels awesome. You’re writing working code quickly and because of your growing suite of unit tests, you have the confidence to make sweeping changes to improve the design.
Next on my list of things to understand was mocking. I had seen it used, but never quite understood the point. Then I downloaded Rhino.Mocks, a very well-respected mock object framework by Oren Eini (aka Ayende Rahien), and decided to take mocking for a spin. Mocking is all about decoupling the class being designed from its dependencies. So if you’re writing a service layer, you can mock out the data layer. The data layer doesn’t even need to exist. You are basically substituting a dynamically generated stub. I had some unit tests that we too closely coupled to the database, which meant they were slow to run and failed miserably if the database wasn’t available. When you’re testing whether your data layer is mapping properly, you need to touch the database, but you can test your presentation, workflow, domain, and even large parts of your data layer without a live database. Unfortunately I couldn’t. Let’s take a look at a test for ensuring that the data layer’s Identity Map is implemented correctly:
[Test]
public void ShouldReturnSameInstanceWhenRetrievingSameDepartment() {
DepartmentRepository repository = new DepartmentRepository();
IList<Department> departments = repository.FindAll();
foreach(Department d1 in departments) {
Assert.IsNotNull(d1);
Department d2 = repository.FindById(d1.Id);
Assert.IsNotNull(d2);
Assert.AreSame(d1, d2);
}
}
I wanted to mock out DepartmentRepository’s dependencies, but I couldn’t get to them. They were internal to DepartmentRepository’s implementation. What to do? Dependency injection to the rescue. Make DepartmentRepository take its dependencies through a constructor (or property setters).
[Test]
public void ShouldReturnSameInstanceWhenRetrievingSameDepartment() {
DepartmentRepository repository = new DepartmentRepository(new DepartmentMapper());
IList<Department> departments = repository.FindAll();
foreach(Department d1 in departments) {
Assert.IsNotNull(d1);
Department d2 = repository.FindById(d1.Id);
Assert.IsNotNull(d2);
Assert.AreSame(d1, d2);
}
}
DepartmentMapper has all the database access logic – TSQL, stored proc names, NHibernate code, or whatever strategy you’re using. DepartmentRepository contains all the database agnostic stuff, such as whether an instance is currently loaded. So now I could mock the DepartmentMapper like so:
[Test]
public void ShouldReturnSameInstanceWhenRetrievingSameDepartment() {
MockRepository mockery = new MockRepository();
IDepartmentMapper mapper = mockery.CreateMock<IDepartmentMapper>();
mockery.ReplayAll();
DepartmentRepository repository = new DepartmentRepository(mapper);
IList<Department> departments = repository.FindAll();
foreach(Department d1 in departments) {
Assert.IsNotNull(d1);
Department d2 = repository.FindById(d1.Id);
Assert.IsNotNull(d2);
Assert.AreSame(d1, d2);
}
mockery.VerifyAll();
}
That still doesn’t do much because I need to tell the mocked mapper to pass back some dummy data. Not too hard to do…
[Test]
public void ShouldReturnSameInstanceWhenRetrievingSameDepartment() {
MockRepository mockery = new MockRepository();
IDepartmentMapper mapper = mockery.CreateMock<IDepartmentMapper>();
IList<Department> mockDepartments = new List<Department>();
for(int i = 0; i < 4; i++) {
mockDepartments.Add(mockery.CreateMock<Department>());
}
Expect.Call(mapper.FindAll()).Return(mockDepartments);
mockery.ReplayAll();
DepartmentRepository repository = new DepartmentRepository(mapper);
IList<Department> departments = repository.FindAll();
foreach(Department d1 in departments) {
Assert.IsNotNull(d1);
Department d2 = repository.FindById(d1.Id);
Assert.IsNotNull(d2);
Assert.AreSame(d1, d2);
}
mockery.VerifyAll();
}
This was feeling all wrong. All I wanted to do was stub out my data layer and I was practically having to “explain” to the mock object the internal implementation of the DepartmentRepository class. I scratched my head for awhile. Left it, came back to it, scratched my head some more. I was missing something about mocking and it felt like something big. Then my second epiphany hit. Unit testing in this way is all about blackbox. You are testing your API. When I call this method with these parameters, I get this result. You don’t care how the method is implemented, just that you get the expected result. Mocking is all about whitebox. You are designing how the method (and hence the class) interacts with its dependencies. You can’t simply drop in mocks to decouple a blackbox unit test from its dependencies. The types of unit tests that you write with and without mocks are fundamentally different and you need both. (If you simply need to decouple your unit tests from their dependencies, you can use stubs, which are objects that return dummy data.) Without mocks, you are writing blackbox tests that specify the inputs and outputs of an opaque API. With mocks, you are writing whitebox tests that specify how a class and its instances interact with its dependencies. A subtle difference, but an important one! So here is the completed, whitebox unit test:
[Test]
public void ShouldReturnSameInstanceWhenRetrievingSameDepartment() {
MockRepository mockery = new MockRepository();
IDepartmentMapper mapper = mockery.CreateMock<IDepartmentMapper>();
IList<IDepartment> mockDepartments = new List<IDepartment>();
for(int i = 0; i < 4; i++) {
IDepartment department = mockery.CreateMock<IDepartment>();
mockDepartments.Add(department);
Expect.Call(department.Id).Return(i);
Expect.Call(mapper.FindById(i)).Return(department);
}
Expect.Call(mapper.FindAll()).Return(mockDepartments);
mockery.ReplayAll();
DepartmentRepository repository = new DepartmentRepository(mapper);
IList<IDepartment> departments = repository.FindAll();
foreach(IDepartment d1 in departments) {
Assert.IsNotNull(d1);
IDepartment d2 = repository.FindById(d1.Id);
Assert.IsNotNull(d2);
Assert.AreSame(d1, d2);
}
mockery.VerifyAll();
}
Let me make a few comments in closing. The MockRepository is usually created in SetUp and mockery.VerifyAll() is called in TearDown. I typically have various helper methods for configuring the mock objects as I use them in multiple unit tests. ReplayAll is important because it switches Rhino.Mocks from record mode (these are the calls you should be expecting and this is how you should respond) to play mode where real calls are being made to the mock objects.
Another thing to note is the heavy use of interfaces because it makes mocking easier. With classes, you can only mock virtual methods/properties because the mocking framework dynamically creates a derived class. (The method/property needs to be virtual so the derived mock object can override the functionality.) This is one reason why TDD code typically makes such heavy use of interfaces. Lastly the use of dependency injection, which is necessary so that we can mock in the first place. You need a way to substitute your mock easily for the real object that it’s replacing. By using TDD with mocking, you have to create a loosely-coupled, easily tested design in order to use mock objects in the first place. Remember, mocking is useful for whitebox testing isolated classes while blackbox testing is useful for verifying the functionality of an API.
* This isn’t to say that UML is worthless. I use it frequently to whiteboard ideas. It’s a good for communicating object structures in common language. I do however think that days or weeks of writing nothing but UML is worthless, a view I didn’t hold a few years ago. The basic problem with UML is that it’s too easy to design something overly complex or completely unworkable. We’ve all had it happen that you start implementing a nice-looking UML diagram and you slap your head saying, “Oops, forgot about that small detail.” Or you realize that what looks like a perfectly reasonable assumption is completely false. TDD values writing working code. Working code tends to quickly identify those gotchas we always run into in software development.
** Jean-Paul Boodhoo does a great job explaining the difference between testing and behaviour specification here. He also mentions a new tool, NSpec, which is very similar in flavour to NUnit, but highlights the behaviour specification aspect of TDD, or behaviour driven design (BDD) as some people are now calling it.
Ryan Byington (BCLTeam Blog) just posted some great information on how to query performance counters as a non-admin on Windows Server 2003, Windows XP x64 Edition, and Vista:
How to Read Performance Counters Without Administrator Privileges
You are running as a non-admin, aren’t you?
.NET Framework 3.0 or 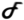 (The Framework Formerly Known as WinFX – TFFKAWFX – or more simply The Framework) has hit the RC1 milestone. Congratulations to the entire Microsoft team. We’re getting very close to a time when we can deploy production applications* using Windows Communication Foundation (WCF) aka Indigo, Windows Presentation Foundation (WPF) aka Avalon, Windows CardSpace (WCS) aka InfoCard, and Windows Workflow (WF) aka No Widely Spread Codename. You can get the latest bits here**:
(The Framework Formerly Known as WinFX – TFFKAWFX – or more simply The Framework) has hit the RC1 milestone. Congratulations to the entire Microsoft team. We’re getting very close to a time when we can deploy production applications* using Windows Communication Foundation (WCF) aka Indigo, Windows Presentation Foundation (WPF) aka Avalon, Windows CardSpace (WCS) aka InfoCard, and Windows Workflow (WF) aka No Widely Spread Codename. You can get the latest bits here**:
- Microsoft Pre-Release Software Microsoft .NET Framework 3.0 – Release Candidate
- Readme for Microsoft Prerelease Software .NET Framework 3.0 (Release Candidate Build)
- Microsoft® Windows® Software Development Kit (SDK) for RC 1 of Windows Vista and .NET Framework 3.0 Runtime Components
- Microsoft Visual Studio Code Name “Orcas” Community Technology Preview – Development Tools for .NET Framework 3.0
- Microsoft® Visual Studio® 2005 Extensions for Windows® Workflow Foundation Release Candidate 5
* We’ve got GoLive licenses for the technologies, but I know my clients want RTM before they’ll even consider it for their projects.
** As of this writing, NetFx3.com still points to the July CTP bits. I would expect it to point to the RC1 bits within the next few days.
Here’s an interesting bit of CLR trivia for you. The CLR behaves differently with respect to how aggressively it considers references dead depending on whether or not a debugger is attached. Take the following code as an example:
public void Foo() {
Bar b = new Bar();
// Do some stuff with b
for(int i = 0; i < int.MaxValue; i++) {
DoSomething();
}
// What does b point to here?
// What if we add GC.KeepAlive(b);
}
Note that the local variable, b, is not referenced in the loop or afterwards. If we are debugging the application and examine the local variable, b, after the loop, b still points to the new Bar instance created at the top of the method because b is still accessible in the current scope. If a debugger is not attached, the GC notes that b isn’t used in the loop or afterward and collects it aggressively. The reason for the difference in behaviour is for ease of debugging.
Another interesting note is the effect of GC.KeepAlive. By adding a call to GC.KeepAlive to the end of the Foo method, we are extending the lifetime of b, regardless of whether a debugger is attached or not, because we are passing the b reference to a method. The method body of GC.KeepAlive doesn’t contain any code. Its sole purpose is to keep the reference alive so that it is not collected by the GC.
Thanks to everyone who attended my talk on Introducing Windows CardSpace. It was one of the liveliest talks I’ve given. I had lots of great questions throughout the presentation and some great discussions with people during and after. I’ve posted the slidedeck here (5086 KB). Following is a list of resources (reproduced from the slidedeck) for those of you who want to learn more about Windows CardSpace.
Windows CardSpace
Whitepapers
Identity Blogs
Overall I’ve had good first impressions of Team Foundation Server, which I installed and configured for a client. We installed TFS Workgroup Edition to get started and later wanted to upgrade to the full version, which the client acquired through volume licensing. Upgrading from Workgroup (or Trial) Edition to the full version using a volume license key (VLK) is far from well-documented. Here’s the steps:
- Find your license key by browsing your TFS (VLK) install media for the file DVD-ROM:\\atdt\setup.sdb and open it in Notepad. Go to the bottom of the file (or search for [Product Key].
- On the TFS box*, start Add/Remove Programs.
- Change/Remove Microsoft Visual Studio 2005 Team Foundation Server.
- Select update product key and enter the product key you found in step 1. You’ll have to type it in manually or copy/paste in groups of 5 characters.
- Click OK and TFS should restart. You are now running the full version of TFS.
You can optionally remove users from the [SERVER]\Team Foundation Licensed Users group as this group is only used in Workgroup mode. I recommend removing everyone from this group as it will reduce future confusion if you ever have to troubleshoot authorization issues with TFS.
* Repeat these steps on both application and data tier boxes if you have a multi-server installation.
I’ll be talking about Microsoft’s new identity metasystem, Windows CardSpace, at the Calgary .NET User Group on August 15, 2006 starting at 5pm. The event will be held at Calgary Place, Tower 1 – 11th Floor (3rd Street SW, between 4th Ave SW and 5th Ave SW). Registration is available through the Calgary .NET User Group website. The event is kindly being sponsored by IRM Systems. Here’s the session abstract:
Windows CardSpace (formerly “InfoCard”) is a Microsoft .NET Framework version 3.0 (formerly WinFX) component that provides the consistent user experience required by the identity metasystem. It is specifically hardened against tampering and spoofing to protect the end user’s digital identities and maintain end-user control. Password fatigue and online fraud is a growing problem and is shaking users’ confidence in the safety and security of the Internet. Windows CardSpace is a new technology from Microsoft that helps address the problem of managing and disclosing identity information.
Windows CardSpace implements the core of the Identity Metasystem, using open standard protocols to securely negotiate, request and broker identity information between trusted identity providers and requesters. In this session, learn about the rationale behind the Identity Metasystem, Windows CardSpace and how technologies including the Windows Communication Foundation can help you easily integrate a secure, consistent identity infrastructure into your own applications, Web sites and Web services.
UPDATE: Jean-Paul Boodhoo will be presenting the second part of Evolving to Patterns. So you get to hear about two great topics at one event. Come one, come all! Jean-Paul is a very passionate and knowledgeable speaker about many topics, but especially around patterns and test-driven development (TDD).
UPDATE UPDATED: Jean-Paul Boodhoo has unfortunately been called out of town on a family matter and will not be able to present Tuesday night. Calgary .NET is planning to have him present the second part of Evolving to Patterns at a future event. Instead I’ll be covering more of CardSpace.